


I work on artificial intelligence and games. I research and develop methods for making games more fun, easier to design and develop, more adaptive, or just to enable games and interactive experiences that we cannot yet create. I'm interested in all kinds of games that people actually play: video games, board games, card games or mind games. When it comes to AI techniques I'm flexible and willing to engage with all kinds of methods, but my methodological roots are in evolutionary computation and neural networks.
Read more about my work with AI and gaming.
University of Essex 2007
Doctor of Philosophy, Computer Science
University of Sussex 2003
Master of Science, Evolutionary and Adaptive Systems
Lund University 2002
Bachelor of Arts, Philosophy
Research Briefs
NYU Tandon School of Engineering researchers test AI systems’ ability to solve The New York Times’ Connections puzzle
Can artificial intelligence (AI) match human skills for finding obscure connections between words?
Researchers at NYU Tandon School of Engineering turned to the daily Connections puzzle from The New York Times to find out.
Connections gives players five attempts to group 16 words into four thematically linked sets of four, progressing from “simple” groups generally connected through straightforward definitions to “tricky” ones reflecting abstract word associations requiring unconventional thinking.
In a study that will be presented at the IEEE 2024 Conference on Games – taking place in Milan, Italy from August 5 - 8 – the researchers investigated whether modern natural language processing (NLP) systems could solve these language-based puzzles.
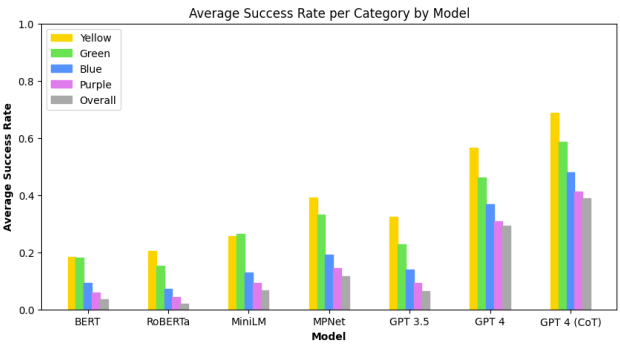
With Julian Togelius, NYU Tandon Associate Professor of Computer Science and Engineering (CSE) and Director of the Game Innovation Lab, as the study’s senior author, the team explored two AI approaches. The first leveraged GPT-3.5 and recently-released GPT-4, powerful large language models (LLMs) from OpenAI, capable of understanding and generating human-like language. The second approach used sentence embedding models, namely BERT, RoBERTa, MPNet, and MiniLM, which encode semantic information as vector representations but lack the full language understanding and generation capabilities of LLMs.
The results showed that while all the AI systems could solve some of the Connections puzzles, the task remained challenging overall. GPT-4 solved about 29% of puzzles, significantly better than the embedding methods and GPT-3.5, but far from mastering the game. Notably, the models mirrored human performance in finding the difficulty levels aligned with the puzzle's categorization from "simple" to "tricky."
"LLMs are becoming increasingly widespread, and investigating where they fail in the context of the Connections puzzle can reveal limitations in how they process semantic information,” said Graham Todd, PhD student in the Game Innovation Lab who is the study’s lead author.
The researchers found that explicitly prompting GPT-4 to reason through the puzzles step-by-step significantly boosted its performance to just over 39% of puzzles solved.
“Our research confirms prior work showing this sort of ‘chain-of-thought’ prompting can make language models think in more structured ways,” said Timothy Merino, PhD student in the Game Innovation Lab who is an author on the study. “Asking the language models to reason about the tasks that they're accomplishing helps them perform better.”
Beyond benchmarking AI capabilities, the researchers are exploring whether models like GPT-4 could assist humans in generating novel word puzzles from scratch. This creative task could push the boundaries of how machine learning systems represent concepts and make contextual inferences.
The researchers conducted their experiments with a dataset of 250 puzzles from an online archive representing daily puzzles from June 12th, 2023 to February 16th, 2024. Along with Togelius, Todd and Merino, Sam Earle, a PhD student in the Game Innovation Lab, was also part of the research team. The study contributes to Togelius’ body of work that uses AI to improve games and vice versa. Togelius is the author of the 2019 book Playing Smart: On Games, Intelligence, and Artificial Intelligence.
arXiv:2404.11730v2 [cs.CL] 21 Apr 2024
Authors
- Julian Togelius

NYU Tandon researchers mitigate racial bias in facial recognition technology with demographically diverse synthetic image dataset for AI training
Facial recognition technology has made great strides in accuracy thanks to advanced artificial intelligence (AI) models trained on massive datasets of face images.
These datasets often lack diversity in terms of race, ethnicity, gender, and other demographic categories, however, causing facial recognition systems to perform worse on underrepresented demographic groups compared to groups ubiquitous in the training data. In other words, the systems are less likely to accurately match different images depicting the same person if that person belongs to a group that was insufficiently represented in the training data.
This systemic bias can jeopardize the integrity and fairness of facial recognition systems deployed for security purposes or to protect individual rights and civil liberties.
Researchers at NYU Tandon School of Engineering are tackling the problem. In a recent paper, a team led by Julian Togelius, Associate Professor of Computer Science and Engineering (CSE) revealed it successfully reduced facial recognition bias by generating highly diverse and balanced synthetic face datasets that can train facial recognition AI models to produce more fair results. The paper’s lead author is Anubhav Jain, Ph.D. candidate in CSE.
The team applied an "evolutionary algorithm" to control the output of StyleGAN2, an existing generative AI model that creates high-quality artificial face images and was initially trained on the Flickr Faces High Quality Dataset (FFHQ). The method is a "zero-shot" technique, meaning the researchers used the model as-is, without additional training.
The algorithm the researchers developed searches in the model’s latent space until it generates an equal balance of synthetic faces with appropriate demographic representations. The team was able to produce a dataset of 13.5 million unique synthetic face images, with 50,000 distinct digital identities for each of six major racial groups: White, Black, Indian, Asian, Hispanic and Middle Eastern.
The researchers then pre-trained three facial recognition models — ArcFace, AdaFace and ElasticFace — on the large, balanced synthetic dataset they generated.
The result not only boosted overall accuracy compared to models trained on existing imbalanced datasets, but also significantly reduced demographic bias. The trained models showed more equitable accuracy across all racial groups compared to existing models exhibiting poor performance on underrepresented minorities.
The synthetic data proved similarly effective for improving the fairness of algorithms analyzing face images for attributes like gender and ethnicity categorization.
By avoiding the need to collect and store real people's face data, the synthetic approach delivers the added benefit of protecting individual privacy, a concern when training AI models on images of actual people’s faces. And by generating balanced representations across demographic groups, it overcomes the bias limitations of existing face datasets and models.
The researchers have open-sourced their code to enable others to reproduce and build upon their work developing unbiased, high-accuracy facial recognition and analysis capabilities. This could pave the way for deploying the technology more responsibly across security, law enforcement and other sensitive applications where fairness is paramount.
This study — whose authors also include Rishit Dholakia (’22) MS in Computer Science, NYU Courant; and Nasir Memon, Dean of Engineering at NYU Shanghai, NYU Tandon ECE professor and faculty member of NYU Center for Cybersecurity — builds upon a paper the researchers shared at the IEEE International Joint Conference on Biometrics (IJCB), September 25-28, 2023.
Anubhav Jain , Rishit Dholakia , Nasir Memon , et al. Zero-shot demographically unbiased image generation from an existing biased StyleGAN. TechRxiv. December 02, 2023
Authors
- Julian Togelius,
- Anubhav Jain,
- Nasir Memon
Research Centers, Labs, and Groups

Game Innovation Lab
The Game Innovation Lab brings together faculty and students from the School ...

NYU Tandon Future Labs
The NYU Tandon Future Labs are business incubators for a ...